
Executive Summary
This white paper presents the findings of our comprehensive evaluation of leading Large Language Models (LLMs) for production applications. In May 2025, we conducted rigorous testing of six state-of-the-art LLMs—OpenAI’s o1 and o3-mini, Anthropic’s Claude 3.5 Sonnet and Claude 3 Haiku, and Google’s Gemini 2.5 Pro and 2.5 Flash—to determine their suitability for an AI Agent project focussed on mortgage advisory.
Our evaluation focused on three critical performance metrics that directly impact both user experience and operational costs:
- Speed of response: How quickly models respond to user queries
- Accuracy: Success rates in completing required tasks correctly
- Token cost: The financial implications of model usage at scale
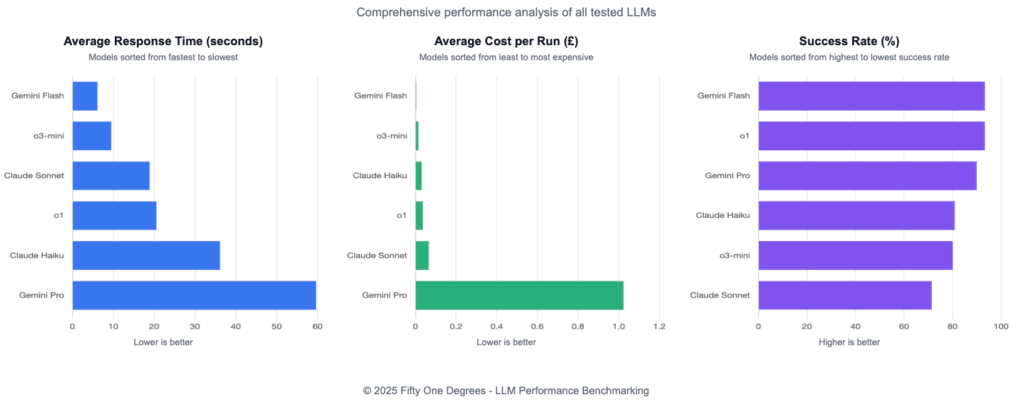
The results revealed that Gemini 2.5 Flash delivered exceptional performance across all metrics:
- Highest success rate (93.33%)
- Fastest average response time (6.17 seconds)
- Lowest cost per run (£0.0043)
OpenAI’s o3-mini also performed strongly with an 80% success rate, good response time (9.5 seconds), and low cost (£0.0146 per run). These findings offer significant implications for organizations seeking to optimize their AI implementations for both performance and cost-efficiency.
Based on our assessment as well as wider industry analysis, we also believe Google’s performance trajectory is likely to result in the Gemini models being the market-leaders over at least the short to medium term. Rapid evolution from Gemini 1.0 Pro (Dec 2023) to the current high-performing Gemini 2.5 Flash indicates momentum is building for future LLM development. Their successful implementation of Mixture-of-Experts (MoE) architecture has enabled exceptional balance between speed, accuracy, and cost efficiency. Organisations should anticipate continued refinement of MoE approaches, further specialised model variants, and potential expansion beyond current 2M token context windows. As providers compete to optimise the intelligence-efficiency balance, we expect increasing focus on domain-specific optimisations for high-value verticals, similar to the performance advantages demonstrated in our mortgage advisory evaluation.
Fifty One Degrees is an AI Consultancy that supports businesses to implement AI, automation and data projects. If you would like to find out more, get in touch.
Introduction
Background and Objectives
As Large Language Models (LLMs) continue to evolve at a rapid pace, organizations face increasingly complex decisions when selecting the optimal model for production applications. The challenge extends beyond simply choosing the most powerful model—it requires finding the right balance between intelligence, speed, and cost for specific use cases.
The primary objective of this study was to evaluate alternatives to our currently deployed OpenAI o1 model for one of our AI Agent projects, our mortgage advisory application. The ideal replacement would need to maintain or improve response accuracy while delivering faster responses and reducing operational costs.
Methodology
We developed a comprehensive testing framework using our existing evaluation suite from the agent project. Each model was assessed against a series of real-world scenarios and use cases specifically tailored to mortgage advisory interactions. These evaluations tested the models’ abilities to:
- Understand user intent in financial contexts
- Provide appropriate responses to mortgage-related queries
- Ask relevant follow-up questions
- Use specialized tools for specific tasks (e.g., cost calculators, application process explainers)
- Maintain conversation flow and user engagement
To ensure reliability, each evaluation was run three times per model, with performance measured across all three critical metrics—speed, accuracy, and cost. This approach allowed us to gather sufficient data to identify meaningful performance differences while managing the scope of the evaluation process.
Model Performance Analysis
Overall Performance Comparison
The table below summarizes the average performance of all evaluated models across our test suite:
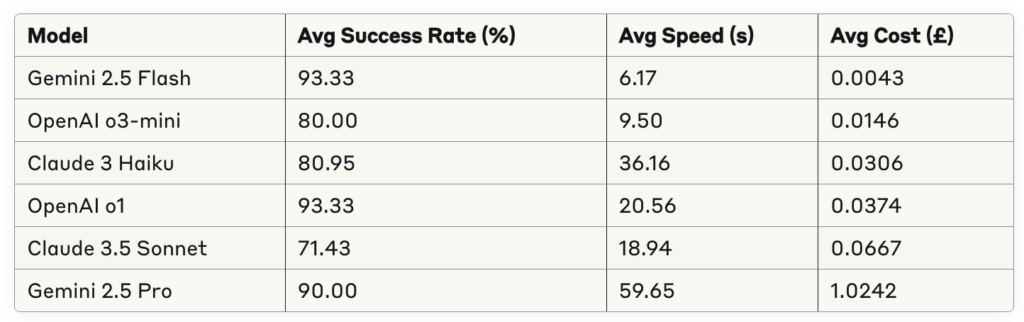
These results demonstrate clear differentiation between models, with Gemini 2.5 Flash delivering exceptional performance across all metrics. While our current model (o1) maintained a high success rate, both o3-mini and 2.5 Flash offered significant improvements in speed and cost efficiency.
Key Performance Insights
Our comprehensive testing revealed several important insights:
1. Speed vs. Accuracy Trade-offs: While most models demonstrated strong accuracy, response speeds varied dramatically. Gemini 2.5 Flash consistently delivered responses 3-10 times faster than our currently deployed o1 model, while maintaining equivalent accuracy.
2. Cost Efficiency: Token costs varied by more than an order of magnitude between models. Gemini 2.5 Flash operated at approximately 11% of the cost of our current o1 model, representing substantial potential savings for production deployments.
3. Model Behavior Variations: We observed interesting differences in how models approached tasks:
- Claude models tended to provide more detailed responses, resulting in higher token counts
- Gemini 2.5 Pro demonstrated high accuracy but at prohibitively high costs and slow speeds
- o3-mini occasionally skipped tool usage but maintained good response quality
4. Specific Use Case Performance: For mortgage advisory applications, the ability to correctly identify customer situations (e.g., later life borrowers) and ask appropriate follow-up questions proved critical. Both o1 and 2.5 Flash excelled in these scenarios.
Key Performance Insights
Our comprehensive testing revealed several important insights:
- Speed vs. Accuracy Trade-offs: While most models demonstrated strong accuracy, response speeds varied dramatically. Gemini 2.5 Flash consistently delivered responses 3-10 times faster than our currently deployed o1 model, while maintaining equivalent accuracy.
- Cost Efficiency: Token costs varied by more than an order of magnitude between models. Gemini 2.5 Flash operated at approximately 11% of the cost of our current o1 model, representing substantial potential savings for production deployments.
- Model Behavior Variations: We observed interesting differences in how models approached tasks:
- Claude models tended to provide more detailed responses, resulting in higher token counts
- Gemini 2.5 Pro demonstrated high accuracy but at prohibitively high costs and slow speeds
- o3-mini occasionally skipped tool usage but maintained good response quality
- Specific Use Case Performance: For mortgage advisory applications, the ability to correctly identify customer situations (e.g., later life borrowers) and ask appropriate follow-up questions proved critical. Both o1 and 2.5 Flash excelled in these scenarios.
Industry Context: LLM Evolution 2022-2025
To place our findings in broader context, it’s important to understand the rapid evolution of LLM performance across the three major providers—OpenAI, Anthropic, and Google Gemini—from 2022 to 2025.
OpenAI Model Evolution (2022-2025)
OpenAI’s development trajectory shows a clear progression in model capabilities, from the initial GPT-3.5 Turbo release in November 2022 with its 4,096-token context window and 70% MMLU score, to the latest GPT-4.1 family launched in April 2025 with 1 million token context windows and significant improvements in coding and reasoning tasks.
A key development has been OpenAI’s introduction of specialized model variants optimized for different performance profiles. The “mini” and “nano” variants released in 2024-2025 represent a strategic move to provide more efficient models that retain much of the intelligence of their larger counterparts while operating at lower cost and higher speeds. This perfectly aligns with our findings regarding o3-mini’s strong performance in our evaluation.
Anthropic Model Evolution (2023-2025)
Anthropic’s Claude models have evolved through distinct generations, starting with Claude 2 in July, 2023, and progressing to the Claude 3.7 Sonnet released in February 2025. A consistent focus throughout has been on creating a tiered family of models (Haiku, Sonnet, Opus) optimized for different use cases—Haiku for speed, Opus for intelligence, and Sonnet as a balance between the two.
The 2024-2025 releases of Claude 3.5 and 3.7 models demonstrated Anthropic’s commitment to improving efficiency without sacrificing quality, with Claude 3.5 Sonnet able to match or exceed the performance of the previous flagship Claude 3 Opus while operating at twice the speed. This trend reflects the broader industry movement toward more efficient models.
Google Gemini Model Evolution (2023-2025)
Google’s Gemini models have displayed perhaps the most dramatic improvements in context length and speed optimization. From the initial Gemini 1.0 Pro in December 2023 with its 32K token context window, Google rapidly developed the Gemini 1.5 series in 2024 with up to 2 million token context windows and the 1.5 Flash variant specifically optimized for speed (207.9 tokens/second).
The Gemini 2.0 and 2.5 series launched in 2025 continued this emphasis on efficiency, with Gemini 2.5 Flash exemplifying the success of Google’s architectural innovations—particularly their implementation of the Mixture-of-Experts (MoE) architecture. This explains the exceptional combination of speed, accuracy, and cost efficiency we observed in our evaluation.
Industry-wide Performance Trends
Several notable trends emerge when examining the evolution of LLMs across all three providers:
- Architectural Innovations: The adoption of Mixture-of-Experts (MoE) architecture, particularly by Google, has enabled dramatic improvements in model efficiency without sacrificing intelligence.
- Expanded Context Windows: All providers have significantly increased context window sizes, from 4-16K tokens in 2022-2023 to 128K-2M tokens in 2024-2025, enabling more complex applications.
- Performance Tiering: By 2025, all major providers have adopted tiered approaches with specialized models optimized for different use cases:
- Speed-optimized models (o3-mini, Claude Haiku, Gemini Flash)
- Balanced models (GPT-4.1, Claude Sonnet, Gemini 1.5 Pro)
- Intelligence-optimized models (o3, Claude Opus, Gemini Pro)
- Speed Improvements: Response speeds have increased dramatically, with the fastest 2025 models (Gemini 2.5 Flash, o3-mini) delivering responses 5-10 times faster than their 2023 counterparts.
- Multimodal Capabilities: By 2024-2025, multimodal inputs became standard across all providers, though our evaluation focused specifically on text-based interactions.
These industry trends directly align with our evaluation findings. The exceptional performance of Gemini 2.5 Flash and the strong results from o3-mini reflect the broader industry’s successful efforts to create more efficient models that maintain high intelligence while significantly improving speed and reducing costs.
Comparison to Public Benchmarks
While our evaluation focused on real-world performance metrics for our specific application, it’s instructive to compare our findings with public benchmark results from sources like the LMSYS Chatbot Arena Leaderboard and the Hugging Face Open LLM Leaderboard. This comparison helps validate whether our application-specific results align with broader industry assessments.
LMSYS Chatbot Arena Comparison
The LMSYS Chatbot Arena evaluates models based on human preferences through pairwise comparisons. As of May 2025, the leaderboard rankings show:
- Google’s Gemini-2.5-Pro-Preview-05-06: Elo score 1446
- OpenAI’s o3-2025-04-16: Elo score 1409
- ChatGPT-4o-latest (2025-03-26): Elo score 1405
- Anthropic’s Claude 3.7 Sonnet (thinking-32k): Elo score 1297
- Anthropic’s Claude 3.7 Sonnet: Elo score 1287
Our findings partially align with these public rankings. The strong performance of Google’s Gemini 2.5 Flash in our evaluation reflects Google’s leading position on the Arena leaderboard, though our testing focused on the Flash variant rather than the Pro model that tops the public leaderboard. Similarly, the strong performance of OpenAI’s o3-mini in our evaluation is consistent with OpenAI’s high rankings.
However, there are notable differences. The Claude models, which rank competitively on the Arena leaderboard, showed mixed results in our testing—strong on some tasks but weaker in others. This highlights an important distinction: public leaderboards measure general capabilities, while our evaluation focused on specific application requirements for mortgage advisory services.
Benchmark Challenges and Limitations
The Stanford AI Index Report and other sources highlight several challenges with public benchmarks that may explain these differences:
- Data Contamination: Models may inadvertently be trained on benchmark data, potentially inflating scores.
- Benchmark Saturation: Leading models are reaching performance ceilings on many established benchmarks.
- Real-world Applicability: Academic benchmarks may not fully capture performance in specific domains or applications.
- Volatility in Human Evaluations: Elo ratings in systems like Chatbot Arena can exhibit volatility when comparing models with similar performance levels.
These limitations underscore the importance of conducting application-specific evaluations like ours, rather than relying solely on public benchmarks to guide model selection.
Cost-Benefit Analysis
To evaluate the financial implications of different model options, we projected the annual cost savings for our AI Agent project based on current usage patterns:
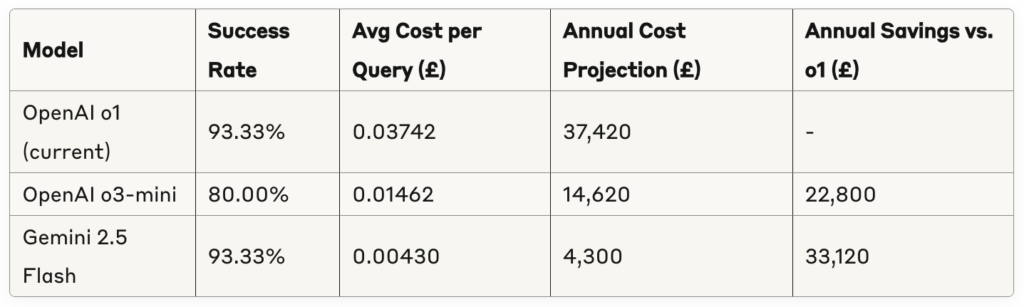
These projections assume 1 million queries per year, which is representative of our current production scale. The potential annual savings of £22,800 to £33,120 represent a substantial operational benefit, especially considering that Gemini 2.5 Flash maintains the same success rate as our current model while delivering faster responses.
However, a pure cost comparison doesn’t account for other important factors:
- Integration Complexity: Switching providers from OpenAI to Google would require additional engineering work to adapt our existing infrastructure.
- Reliability and SLAs: Different providers offer varying service-level agreements and historical reliability metrics.
- Long-term Provider Strategy: Each provider has different development roadmaps and pricing strategies that may impact future costs.
- Risk Mitigation: Maintaining relationships with multiple providers offers strategic advantages in case of service disruptions or significant pricing changes.
Implementation Recommendations
Based on our comprehensive evaluation, we recommend the following implementation strategy.
Short-term Recommendation
Immediate Action: Switch to Gemini 2.5 Flash as your primary model.
This recommendation is based on Gemini 2.5 Flash’s exceptional performance across all metrics:
- Equivalent accuracy to our current model (93.33% success rate)
- 3.3× faster response time (6.17s vs. 20.56s)
- 8.7× cost reduction (£0.0043 vs. £0.0374 per query)
Implementation Approach
- Validation Testing: Conduct a limited real-user test with Gemini 2.5 Flash to verify that the performance observed in our controlled evaluation translates to real-world scenarios.
- Monitoring Framework: Establish comprehensive monitoring of response times, success rates, and user satisfaction metrics to ensure the model performs as expected in production.
Long-term Strategy
Looking beyond the immediate model switch, we recommend:
- Multi-provider Strategy: Maintain integration capabilities with multiple providers (OpenAI, Google, Anthropic) to leverage future improvements and mitigate vendor-specific risks.
- Regular Re-evaluation: Establish a quarterly cadence for evaluating new model releases against our specific use cases.
- Specialized Fine-tuning: Explore fine-tuning options for the highest-impact scenarios where even small improvements in accuracy would deliver significant value.
- Context Window Optimization: Leverage the dramatically expanded context windows (1M+ tokens) in newer models to enhance the application’s memory capabilities.
Conclusion
Our comprehensive evaluation of leading LLMs for the one of our production projects has revealed significant opportunities to improve both performance and cost-efficiency. The exceptional results from Gemini 2.5 Flash demonstrate that the latest generation of efficiency-optimized models can deliver equivalent accuracy to larger models while dramatically improving speed and reducing costs.
These findings reflect broader industry trends in LLM development from 2022 to 2025, where providers have increasingly focused on creating specialized variants optimized for different performance profiles. The rapid pace of innovation across OpenAI, Anthropic, and Google Gemini has led to a rich ecosystem of options for production applications.
For organizations deploying LLMs in production environments, our research underscores the importance of rigorous, application-specific evaluation rather than relying solely on public benchmarks or provider recommendations. The right model choice depends not just on raw capabilities, but on the specific requirements and constraints of each use case.
As we implement these recommendations for our projects, we anticipate not only significant cost savings but also improved user experiences through faster response times. This evaluation framework and methodology will serve as a template for future model assessments, ensuring we continue to leverage the most appropriate AI technologies as the field evolves.


